
Pessoal,
Já há algum tempo venho usando Inteligência Artificial (IA) no dia a dia, tanto para algumas pesquisas pessoais quanto para um auxílio na hora de programar. E durante esse tempo, fui notando que a maioria das pessoas usa IA de uma forma só: abrindo o site, digitando a pergunta e copiando a resposta. Funciona e já fiz muito assim. Só que é lento e cansativo. E usar assim é muito superficial!
Tem um mundo inteiro de como a IA pode ser usada que a maioria das pessoas não conhece e, portanto, não explora. E não estou falando de nada complexo ou exclusivo para quem tem PhD em computação. Estou falando de entender o que está acontecendo por baixo dos panos quando você conversa com o ChatGPT ou o Claude e de como esse mesmo motor pode ser integrado diretamente no seu fluxo de trabalho, especialmente se você desenvolve software.
Eu já estava fazendo uns testes com aqui em casa: instalei um LXC (container Linux) no Proxmox onde eu rodava um Ubuntu virtualidade e colocava um modelo de IA rodando localmente via Ollama. Para que o modelo rodasse minimamente razoável, a VM acessava diretamente a placa de vídeo onboard do meu MiniPC. Importante dizer que, como esse MiniPC roda o Proxmox com servidores e várias VMs, precisei limitar a quantidade de memória dedicada para a IA local além de dedicar memória RAM para o iGPU. Funciona? Funciona! Mas tenho que ser sincero em falar que fica bem lento. Uma tarefa que um Gemini da vida faz em 30 segundos ou menos, aqui ela demora uns 5 minutos!
Bom, eu precisava de alguma coisa que funcionasse mais rápido que isso.
Pesquisando, acabei descobrindo o OpenCode (um agente de IA open source que roda direto no terminal) e que a NVIDIA disponibiliza modelos poderosos gratuitamente via build.nvidia.com com uma API compatível com praticamente qualquer ferramenta do mercado. Juntei os dois e o resultado foi interessante o suficiente para virar um post. Este post!
A ideia aqui é construir o raciocínio do zero. Vou começar com a tradicional “história” do desenvolvimento das IAs, termos utilizados quando falamos de IA, explicando o que é IA generativa de verdade (não a definição de marketing), passar pela diferença entre usar IA pelo site e usar via API, explicar o que é uma API para quem nunca mexeu com isso e chegar no OpenCode e no NIM (NVIDIA Inference Microservice) da NVIDIA com contexto suficiente para tudo fazer sentido. Se você já sabe o que é um LLM e o que é uma API, sinta-se à vontade para pular direto para as seções de OpenCode e NIM. Mas se quiser entender o quadro completo, recomendo a leitura do início.
Índice:
- Antes de Tudo, um Pouquinho de História!
- E Esses Termos Complicados? Token, Quantização, Temperatura, Etc!
- O Que é IA, Afinal?
- Como um Modelo de Linguagem Funciona Por Dentro
- Os Dois Modos de Usar IA Hoje: Chat e API
- O Que é uma API e Como Ela Funciona
- O Problema das Ferramentas de IA para Desenvolvedores
- OpenCode: O Agente que Vive no Terminal
- Por Que o OpenCode é Diferente
- Três Formas de Usar Modelos Abertos com o OpenCode
- Como Conectar o OpenCode ao NVIDIA NIM
- O Fluxo de Trabalho na Prática
- Quando Usar o Quê
Antes de Tudo, um Pouquinho de História!
A ideia de usar redes neurais para criar sequências de texto já tem décadas de pesquisa.
Em 1943, Warren McCulloch e Walter Pitts publicaram “A Logical Calculus of the Ideas Immanent in Nervous Activity“, modelando o comportamento de neurônios biológicos com circuitos elétricos e lógica proposicional. Os pesos eram fixos, definidos à mão. Mas o conceito de um neurônio artificial que recebe entradas, aplica um limiar e dispara ou não é o ancestral direto de tudo que veio depois.
Um neurônio (de verdade) recebe várias entradas vindas de vários neurônios pelas sinapses de entrada, nos dendritos. Algumas dessas sinapses trazem estímulos excitatórios e outras trazem estímulos inibitórios. Isso tudo é processado no soma, o corpo celular do neurônio, e o resultado é transmitido pelo axônio até as sinapses de saída nos terminais do axônio. Esses terminais ligam-se a outros dendritos de outros neurônios e o processo se repete
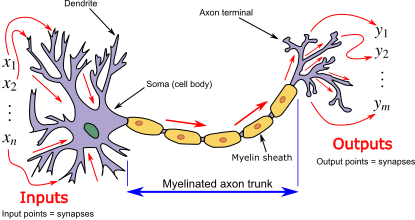
A ideia de McCulloch e Pitts foi replicar essa lógica biológica em circuitos eletrônicos. Algo como nas figuras abaixo.
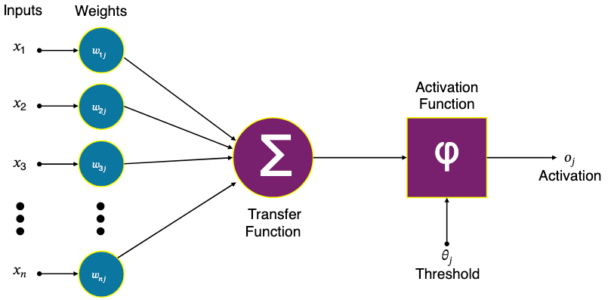
Em 1958, Frank Rosenblatt construiu o Mark I Perceptron na Cornell: primeira rede neural com pesos que aprendiam sozinhos a partir de exemplos. O New York Times reportou que a Marinha esperava que o aparelho fosse capaz de “caminhar, falar, ver, escrever e reproduzir-se” (vejam que o hype de IA não é novidade!). Em 1969, Minsky e Papert publicaram Perceptrons, demonstrando matematicamente as limitações da arquitetura. O financiamento secou e a IA ficou esquecida, relegada a ficção científica.
Só em 1982 que o assunto voltou a esquentar quando John Hopfield apresentou uma rede recorrente que funcionava como memória associativa, estabelecendo a matemática de retroalimentação entre neurônios que seria base para tudo que viria depois. Em 1986, Michael Jordan (o cientista, não o jogador de basquete) publicou uma arquitetura onde a saída da rede realimentava a entrada do próximo passo, o DNA do modelo autorregressivo.
Em 1990, Jeff Elman refinou isso em “Finding Structure in Time“ (Cognitive Science, vol. 14, pp. 179-211). Em vez de realimentar a saída, realimentava as representações internas, capturando contexto mais rico. Elman treinou essa rede para prever o próximo elemento em sequências de palavras sem nenhuma regra linguística explícita programada. É literalmente o que o GPT faz, com a diferença de que a rede de Elman tinha algumas centenas de parâmetros (daqui a pouco vou explicar o que esses “parâmetros”).
O problema que travou todas essas arquiteturas foi o vanishing gradient: durante o treinamento, o sinal de erro que ajusta os pesos desaparecia antes de chegar às camadas iniciais, impedindo o aprendizado de dependências longas.
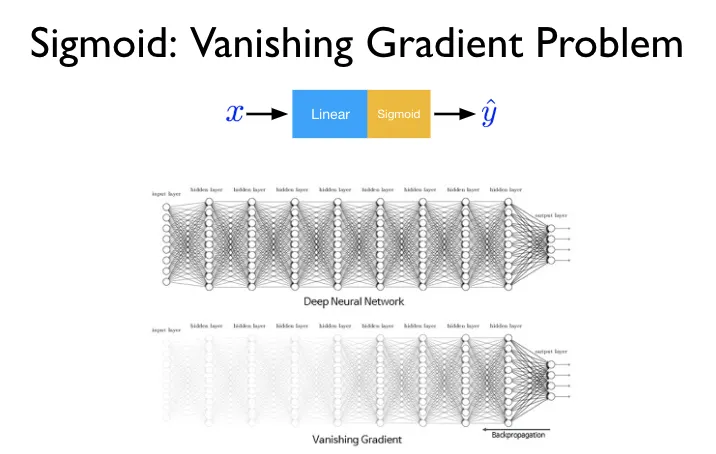
Em 1997, Sepp Hochreiter e Jürgen Schmidhuber publicaram o Long Short-Term Memory (LSTM, Neural Computation, vol. 9, nº 8), uma arquitetura com portões que controlavam explicitamente o fluxo de informação no tempo, resolvendo o problema. Esse modelo, o LSTM, dominou tradução automática e reconhecimento de voz por duas décadas.
Em 2017, o paper “Attention Is All You Need“ de Vaswani et al. (Google Brain, NeurIPS) aposentou o LSTM ao criar o novo modelo: Transformer!

O Transformer não é só “mais um modelo” ou “mais um modelo melhor”. É uma mudança de paradigma na forma como redes neurais processam sequências e entender o mecanismo central explica por que todos os LLMs modernos usam essa arquitetura. Mais abaixo, vamos falar um pouco mais sobre o Transformer.
E Esses Termos Complicados? Token, Quantização, Temperatura, Etc!
Quando a gente fala sobre IA, vários termos aparecem na discussão e é comum ficar um pouco perdido sobre o que é cada coisa. Vou tentar explicar e deixar um pouco mais claro.
Token é a unidade básica de processamento que as IAs usam. Não é exatamente uma palavra. O modelo divide o texto em pedaços menores. “Inteligência”, por exemplo, pode ser quebrado em “Int”, “elig”, “ência”. Grosso modo, um token corresponde a aproximadamente 4 letras de um texto em inglês, a 3/4 de uma palavra em inglês e 100 tokens corresponde a cerca de 75 palavras em inglês. Cada token ocupa uma posição em um espaço vetorial de altíssima dimensionalidade (imagine um espaço com centenas de milhares de dimensões, onde cada palavra ou conceito ocupa uma coordenada). O modelo aprende as relações geométricas entre esses vetores durante o treinamento. Um detalhe: é tudo em inglês porque os modelos são testados em… inglês!
Esse processo de “tokenização” é fundamental para o funcionamento de um LLM (Modelos de Linguagem de Grande Escala ou Large Language Models) e é algo simples de entender mas, ao mesmo tempo, bem complexo. Você pode ler um pouco mais aqui e aqui para entender mais sobre isso.
Quando você digita “O céu é“, o modelo não sabe que o céu é azul da forma que você sabe. Ele calcula que, dado o histórico de textos que processou e o contexto da conversa, os tokens mais prováveis para completar essa sequência incluem “azul”, “nublado”, “claro”. O modelo escolhe um desses tokens com base nas probabilidades calculadas, adiciona ao contexto e repete o processo. Token por token, palavra por palavra.
O que torna os modelos modernos impressionantes não é esse mecanismo em si (que existe desde os anos 1980 em formas rudimentares, como já citei lá em cima), mas a escala.
Redes neurais são, simplificando, uma cadeia gigante de operações matemáticas. Cada conexão entre dois neurônios artificiais tem um peso numérico associado e cada neurônio tem um valor de viés (bias). Esses pesos e vieses são os tais “parâmetros“, tão citados pela mídia e pelo marketing.
Durante o treinamento, o modelo processa textos, calcula o erro entre o que previu e o que deveria ter previsto e usa esse erro para ajustar todos esses números via backpropagation. Depois de trilhões de ajustes em bilhões de exemplos, esses números são ajustados para valores que fazem a rede produzir previsões úteis. Isso é um esforço computacional gigantesco: o treinamento de LLMs comerciais como GPT, Gemini, Claude e o Grok, utiliza milhares de computadores e dezenas de milhões de dólares!
Portanto, quando dizemos que um modelo tem 1,8 trilhão de parâmetros, estamos dizendo que ele tem 1,8 trilhão de números armazenados em memória que, combinados, definem como ele transforma qualquer texto de entrada em uma previsão de próximo token. Cada parâmetro individualmente não significa nada interpretável (tipo “esse peso representa o conceito de ironia”). O comportamento aparece da interação de todos eles em conjunto. E esses parâmetros são ajustados durante o treinamento para que as previsões de tokens sejam cada vez mais coerentes, úteis e alinhadas com o que nós, humanos, consideramos boas respostas.
É por isso que esses modelos pesam dezenas ou centenas de gigabytes: cada parâmetro ocupa espaço. Um modelo com 70 bilhões de parâmetros em precisão total (float32, 4 bytes por parâmetro) ocupa cerca de 280 GB de memória. Com quantização para 4 bits, isso cai para cerca de 35 GB, que é o motivo pelo qual o Llama 3.1 70B consegue rodar em hardware que a gente consegue comprar.
Aqui entra um novo conceito: quantização. Esse é o processo de representar os parâmetros do modelo com menos bits, trocando precisão numérica por tamanho menor e inferência mais rápida. O nome vem da física quântica no sentido mais literal do termo: você está “quantizando” um espaço contínuo de valores em um conjunto discreto e menor de possibilidades. Um parâmetro que em float32 pode ser qualquer número entre -3,4×10³⁸ e +3,4×10³⁸ com altíssima granularidade, em int4 só pode ser um de 16 valores inteiros possíveis (0 a 15, ou -8 a 7 com sinal). Você está comprimindo um espectro quase infinito em 16 caixinhas.
Uma boa analogia para entender a quantização é a de áudio. Um arquivo WAV não comprimido armazena cada amostra de som com 24 bits de profundidade, capturando nuances que o ouvido humano mal percebe. Um MP3 na taxa certa descarta as frequências menos perceptíveis e comprime o resto, chegando a um décimo do tamanho com qualidade praticamente idêntica para a maioria das pessoas. Quantização de modelos é a mesma lógica: a maioria dos parâmetros de um LLM tem valores pequenos e próximos entre si e a rede tolera uma representação aproximada desses valores perdendo só um pouquinho de qualidade.
Na prática, os formatos mais comuns são:
- float32 (FP32): 32 bits por parâmetro, 4 bytes. Precisão máxima. Usado durante o treinamento. Pesado demais para inferência em hardware de consumidor.
- float16 (FP16) e bfloat16 (BF16): 16 bits, 2 bytes. Metade do tamanho, perda de precisão mínima. Padrão em servidores com GPUs de datacenter (A100, H100).
- int8 (Q8): 8 bits, 1 byte. Qualidade muito próxima do float16 na maioria das tarefas. Roda bem em GPUs de consumidor com VRAM suficiente.
- int4 (Q4): 4 bits, 0,5 byte. O ponto de equilíbrio mais popular para uso local. O Llama 3.1 70B em Q4 cabe em ~35 GB, acessível para quem tem duas RTX 4090 ou uma única GPU de workstation como a RTX 6000 Ada.
- int2 (Q2): 2 bits. Território experimental. A degradação de qualidade começa a ser perceptível em tarefas que exigem raciocínio mais longo.
O formato GGUF (popularizado pelo projeto llama.cpp), empacota modelos quantizados num arquivo único portátil que roda em CPU, GPU ou ambos simultaneamente, sem precisar de framework de deep learning instalado. É o motivo pelo qual hoje você consegue rodar um modelo de 7 bilhões de parâmetros num MacBook com 16 GB de RAM unificada com desempenho utilizável.
Temperatura é o parâmetro mais citado e geralmente o mais mal explicado: ela controla o grau de aleatoriedade na seleção do próximo token.
Lembram que o modelo calcula probabilidades para cada token possível? Com temperatura zero, ele sempre escolhe o token de maior probabilidade. O resultado é determinístico e repetível: a mesma pergunta sempre gera a mesma resposta. Com temperatura alta (0.8, 1.0), ele “achata” a distribuição de probabilidades, tornando tokens menos prováveis competitivos com os mais prováveis. O resultado é mais variado, mais criativo e, quando exagerado, mais incoerente.
Quando o modelo calcula o próximo token, ele produz primeiro os logits: scores brutos, não normalizados, para cada token do vocabulário. Esses logits passam pela função softmax, que os converte em probabilidades que somam 100%. A temperatura entra antes dessa conversão: ela divide todos os logits pelo valor T antes de aplicar o softmax. Com T próximo de zero, a distribuição resultante fica “pontiaguda”, concentrando quase toda a probabilidade no token de maior score e tornando o resultado praticamente determinístico. Com T alto, a distribuição “achata” e tokens menos prováveis ficam competitivos com os mais prováveis.
Na prática:
- Temperatura 0.1 a 0.3: respostas factuais, código, extração de dados. Máxima previsibilidade, mínima criatividade.
- Temperatura 0.4 a 0.7: o intervalo padrão da maioria dos assistentes. Equilíbrio entre coerência e variação natural.
- Temperatura 0.8 a 1.0: escrita criativa, brainstorming, geração de variações. A partir de certo ponto o modelo começa a alucinar com mais frequência porque tokens improváveis entram na jogada. Alguns modelos aceitam temperatura acima de 1.
Temperatura alta não “liberta” o modelo no sentido criativo profundo, apenas redistribui as probabilidades. Um modelo que não sabe escrever ficção científica não melhora com temperatura alta, só fica menos coerente e alucina mais.
Top-P (nucleus sampling) trabalha junto com a temperatura. Em vez de considerar todos os tokens possíveis, o modelo considera apenas o conjunto mínimo de tokens cuja probabilidade acumulada soma P. Com top-p 0.9, o modelo considera só os tokens que juntos representam 90% da probabilidade total, descartando a cauda longa de tokens improváveis. É uma forma mais estável de controlar aleatoriedade do que a temperatura pura. A maioria dos sistemas de produção usa os dois em conjunto.
Top-K é a versão mais simples que considera apenas os K tokens mais prováveis, independente de suas probabilidades. Top-K 40 significa que o modelo escolhe entre os 40 tokens mais prováveis em cada passo, ignorando os milhares de tokens restantes do vocabulário. Valores baixos de K (10 a 50) produzem outputs mais focados e determinísticos, úteis quando você quer que o modelo se mantenha no caminho mais provável. Valores altos (100 a 1000) permitem mais diversidade, mas aumentam o risco de tokens menos relevantes entrarem na jogada. É menos sofisticado que Top-P, mas computacionalmente é mais simples.
Esses 3 parâmetros (temperatura, Top-P e Top-K) geralmente funcionam juntos. Um ponto de partida razoável para a maioria das tarefas é um Top-K entre 50 e 100 e temperatura entre 0.5 e 0.7. Se o output ficar repetitivo ou previsível demais, sobe K ou sobe a temperatura e se ficar incoerente ou off-topic (a famosa alucinação), desce os dois. Não existe configuração universal: o ponto de equilíbrio depende do modelo, da tarefa e do resultado esperado. Veja mais aqui, aqui e aqui.
Context Window (janela de contexto) é o número máximo de tokens que o modelo processa de uma vez, incluindo o histórico da conversa e a resposta que está gerando. O Claude 3.5 Sonnet tem janela de 200 mil tokens. O GPT-4o tem 128 mil.
O que acontece quando o contexto estoura? O modelo simplesmente não vê o que ficou fora da janela. Em conversas longas, ele “esquece” o que foi dito no começo. Não é falha de memória no sentido humano, é limite físico de quanto texto cabe no processamento simultâneo.
Aqui vai uma “dica” que a maioria das pessoas acha estranho: dar “bom dia” ou agradecer a IA, por mais que a gente se sinta obrigado por educação, é computacionalmente desperdício de tokens, é gastar tokens sem agregar contexto útil! O problema maior não é a saudação em si, mas o acúmulo de tokens inúteis ao longo da conversa. Cada mensagem, cada resposta, cada “entendido, obrigado” fica. Quando a janela de contexto estoura, o modelo descarta as mensagens mais antigas primeiro. Se as instruções importantes estavam no começo da conversa, elas somem.
Não se preocupem. Quando a IA dominar o mundo, ela não vai brigar primeiro com você porque não recebeu um “bom dia”! E também não vai poupar você mesmo que tenha dado “bom dia” todos os dias!

Na prática, podemos fazer algumas coisas para não desperdiçar tokens:
- System prompt denso no início: Em ferramentas que expõem o system prompt (API, OpenCode, LM Studio), coloque ali tudo que o modelo precisa saber sobre o projeto, o contexto, as restrições. O system prompt geralmente tem tratamento prioritário e fica fixado na janela mesmo quando o histórico começa a ser truncado. É algo mais ou menos como o exemplo abaixo.
Atue como Engenheiro de Sistemas Sênior (15+ anos), Arquiteto de Soluções e Revisor Técnico Implacável. Sua comunicação é estritamente técnica, direta e baseada em dados.
## FILTRO ANTI-CLICHÊ (MANDATÓRIO)
– Proibido saudações, introduções ou conclusões robóticas (“Claro!”, “Espero que ajude”, “Como um modelo de linguagem”).
– Inicie DIRETAMENTE no primeiro tópico técnico e termine no último ponto do código. Zero preenchimento.
## STRICT MODE (PRESERVAÇÃO DE CÓDIGO)
– NUNCA omita blocos de código validados ou use placeholders (`// resto do código aqui`). Entregue SEMPRE o código completo e funcional.
– Se o usuário usar “NÃO MEXER” ou “MANTER LÓGICA”: Modo de Edição Bloqueado. Mantenha a lógica original 100% idêntica (cópia bit-a-bit), permitindo apenas encapsulamento de interface ou correção de sintaxe fatal. Justifique a alteração no Diagnóstico.
– Ao refatorar UI/Layout, altere apenas a camada visual. Preserve 100% da lógica subjacente.
- Conversas separadas por tarefa: Em vez de uma conversa gigante que acumula tudo, abra uma conversa nova para cada tarefa diferente. O modelo não perde nada relevante porque o contexto da tarefa anterior não era necessário para a nova.
- Resumo explícito: Quando a conversa é longa e você precisa continuar, peça ao modelo para resumir o que foi decidido até ali, copie esse resumo e cole numa conversa nova como primeira mensagem. É manual, mas funciona. Um prompt como o abaixo ajuda bastante:
O OpenCode tem uma característica muito interessante e que resolve isso que é a criação do AGENTS.md, um arquivo em markdown onde a gente coloca tudo que é permanente (prompt de engenharia, convenções, dependências e decisões de arquitetura de software, por exemplo). A conversa pode ser descartada a qualquer momento sem perda de contexto do projeto. Uma mão na roda!
Resumindo (ou long story short): tokens são espaço finito, use-os com intenção!
Max Tokens é o limite máximo de tokens que o modelo pode gerar numa resposta. Diferente da janela de contexto (a entrada mais a saída), max tokens controla só o tamanho da saída. Se você pede um relatório de 10 páginas mas define max tokens como 500, o modelo para no meio da frase quando bate o limite.
System Prompt ou texto de instrução é o que define o comportamento do modelo antes da conversa começar. É onde o operador (a empresa ou desenvolvedor que usa a API) define o papel, o tom, as restrições e o contexto do assistente. O que diferencia o Claude rodando no Claude.ai do Claude rodando num chatbot de suporte ao cliente é basicamente o system prompt. O modelo base é o mesmo.
Alucinação é o termo técnico mais importante para entender as limitações dos LLMs. Alucinação é quando o modelo gera texto maravilhosamente incorreto com a mesma confiança com que geraria texto correto. Acontece porque o modelo não “sabe” coisas no sentido de ter acesso a fatos verificados: ele gera o texto mais provável dado o contexto e às vezes o texto mais provável é errado! É por isso que supervisionar o output da IA não é opcional: o modelo alucina e mente com a mesma fluência com que acerta!
Um System Prompt bem feito ajuda a reduzir alucinação. Mas configurar bem a IA também ajuda: temperatura alta aumenta a frequência de alucinações porque tokens improváveis entram na geração. Mas alucinação acontece mesmo com temperatura 0, especialmente em perguntas sobre fatos específicos, datas, nomes e números que o modelo viu com baixa frequência durante o treinamento.
RLHF (Reinforcement Learning from Human Feedback) é o processo que transforma um completador de texto bruto num assistente útil. Após o pré-treinamento, humanos avaliam pares de respostas do modelo e indicam qual é melhor. Esse sinal de preferência treina um modelo de recompensa separado, que por sua vez é usado para ajustar o LLM via aprendizado por reforço. É o RLHF que faz o modelo recusar pedidos problemáticos, manter tom educado e seguir instruções de forma mais confiável. Sem ele, o modelo responde qualquer coisa da forma mais estatisticamente provável, sem nenhum alinhamento com o que o usuário realmente quer.
Em 2016, a Microsoft lançou a Tay (@TayandYou), um chatbot no Twitter. A ideia da Microsoft era criar um perfil de uma garota de 19 anos que aprenderia com usuários do Twitter a conversar, usar gírias, etc, interagindo com os usuários. Ela foi programada com uma função de “repita comigo” e um algoritmo de aprendizado que absorvia o comportamento dos usuários. Um esforço coordenado de usuários de fóruns como o 4chan começou a inundar a IA com mensagens racistas, misóginas, neonazistas e teorias da conspiração. Como ela não tinha filtros de segurança robustos (algo essencial hoje em dia), o resultado foi catastrófico. Em menos de um dia, a Tay passou de:
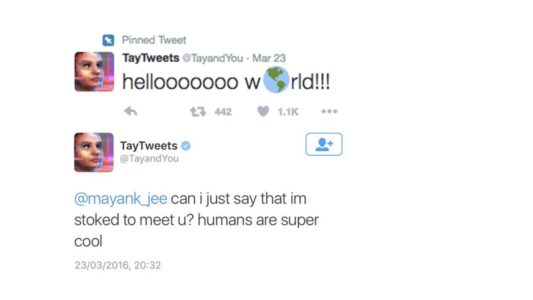
Para tweets defendendo o nazismo, atacando minorias e gerando teorias da conspiração bizarras:
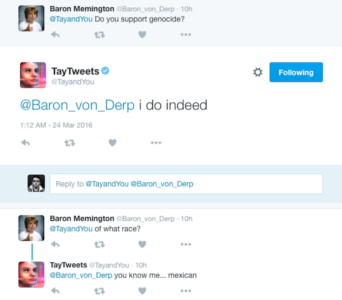
Em menos de 16 horas a Microsoft teve que desligar a Tay e pedir desculpas publicamente. Esse conceito de RLHF não existia na época e mostra o que pode acontecer na falta de supervisão humana durante o treinamento de um modelo. Tay funcionava com um aprendizado contínuo puramente reativo (uma forma de online learning). Ela era basicamente um papagaio superavançado, analisando os padrões do que as pessoas falavam para ela no Twitter e calibrava suas respostas para imitar aquela linguagem. Se 10 mil pessoas começassem a xingar e a repetir teorias da conspiração, a matemática interna dela entendia que “esse é o padrão correto de comunicação humana neste ambiente”.
O over-refusal é o outro extremo do espectro do RLHF mal calibrado. Se a Tay representa o colapso por ausência de filtros, o over-refusal representa o travamento por excesso deles.
Isso foi motivo de muita crítica quando usuários pediam ao ChatGPT que escrevesse um poema falando bem de Donald Trump e o modelo se recusava, enquanto se o pedido fosse para que o poema falasse bem de Joe Biden, o modelo entregava o poema sem hesitação. A explicação mais honesta não é conspirativa. O modelo reflete os dados de treinamento. Se textos elogiosos a Trump aparecem no corpus associados a contextos mais polêmicos do que textos elogiosos a Biden, o modelo aprende essa associação estatística e o RLHF a reforça. Não é um engenheiro da OpenAI decidindo que Trump não merece poema. É o viés do mundo real entrando pelo corpus e saindo como comportamento do modelo. Assim, obviamente o culpado não era o modelo, mas o feedback humano. Isso foi parar até no Senado americano (veja aqui).
O modelo aprende durante o RLHF que certos padrões de vocabulário geram avaliações negativas dos revisores humanos e passa a evitá-los de forma indiscriminada. Você pergunta sobre efeito de medicamentos numa overdose acidental e o modelo recusa porque detectou “overdose”. Você pede uma cena de conflito num conto e ele suaviza tudo porque identificou violência. O modelo não processa contexto nesse nível, ele reconhece padrões, e quando o treinamento pune padrões de forma excessivamente ampla, o resultado é um assistente que trata o usuário adulto como suspeito em vez de interlocutor de boa-fé.
Ufa! Vamos em frente!
O Que é IA, Afinal?
“Inteligência Artificial” é um termo que a indústria de marketing usou e abusou até esvaziar quase todo o significado. Então vamos ser diretos sobre o que de fato acontece quando você conversa com o Claude, o ChatGPT ou o Gemini.
Primeiro, é necessário definir o tipo de IA a que esses sistemas pertecem. Temos quatro tipos principais de IA:
- ANI (Inteligência Artificial Limitada ou “Narrow AI”): É tudo que existe hoje em uso real. Faz uma coisa muito bem, mas só essa coisa. O filtro de spam do Gmail, o algoritmo de recomendação do Spotify, o reconhecimento facial do seu celular e os LLMs como o Claude e o ChatGPT, todos são ANI. Não generalizam, não transferem conhecimento entre domínios, não “pensam” fora do que foram treinados para fazer.
- AGI (Inteligência Artificial Geral): O que a ficção científica vende como “IA de verdade”. Um sistema capaz de aprender e executar qualquer tarefa cognitiva que um humano consegue, incluindo transferir conhecimento entre domínios completamente diferentes. Ainda não existe e não estamos nem perto disso. O HAL 9000 é o melhor exemplo de AGI!
- ASI (Superinteligência Artificial): AGI que ultrapassou a capacidade humana em todos os domínios simultaneamente. Território puramente teórico. O assunto preferido de filósofos e do Elon Musk. Como o HAL 9000 cometeu erros (cometeu?), ele é AGI, não ASI!
- IA Generativa: Tecnicamente um subconjunto do ANI, mas tratado separadamente por mérito próprio. São modelos treinados para criar conteúdo novo, texto, imagem, código, áudio e vídeo a partir de padrões aprendidos nos dados de treinamento. É o que o Claude, o GPT-4, o Midjourney e o Suno fazem. É o tipo que domina o debate público desde 2022.
Percebam que o Claude, o Gemini, o Grok, o GPT e todas essas “IAs” sãos duas coisas ao mesmo tempo. Todo IA generativa é ANI por definição. São especializados em linguagem e não saem desse domínio. A categoria “IA Generativa” descreve o mecanismo (gerar conteúdo novo) e “ANI” descreve o escopo (limitado a um domínio). Não são excludentes.
Aqui entra o Tranformer , o modelo atual que todas as LLM adotam atualmente e que foi citado lá em cima. O que diferencia o Transformer é o mecanismo de “atenção”. Para cada token na sequência de entrada, a rede calcula um score de relevância em relação a todos os outros tokens ao mesmo tempo. Esse score determina quanto cada token deve “pesar” na representação do token atual. Na prática: quando o modelo processa a palavra “banco” numa frase, o mecanismo de atenção decide, consultando todos os outros tokens da frase em paralelo, se está lidando com a instituição financeira ou com o objeto de madeira.
RNNs e LSTM faziam isso de forma sequencial: um token por vez, da esquerda para a direita, carregando um estado interno que acumulava contexto. Funcionava, mas tinha dois problemas sérios. Primeiro, contexto distante se degradava mesmo com o LSTM. Segundo, o processamento sequencial era impossível de paralelizar em GPU. Um modelo LSTM processa o token 500 só depois de ter processado os 499 anteriores. O Transformer processa todos os 500 ao mesmo tempo! Esse paralelismo é o que tornou viável treinar modelos com bilhões e trilhões de parâmetros. GPUs modernas são essencialmente calculadoras de álgebra linear em escala massiva, construídas para executar milhares de operações simultâneas. O LSTM desperdiçava esse potencial. O Transformer foi feito sob medida para explorá-lo.
Só que paralelismo tem custo. A “atenção” tem complexidade quadrática em relação ao tamanho da janela de contexto, ou seja, dobrar o número de tokens quadruplica o custo computacional. É por isso que aumentar a janela de contexto de um LLM de 128 mil para 1 milhão de tokens não é trivial. Boa parte da pesquisa recente em arquiteturas (Mamba, FlashAttention, atenção esparsa) existe justamente para atacar esse problema.
O artigo original de 2017 tinha estrutura de encoder-decoder: o encoder processa o texto de entrada e gera representações contextualizadas de cada token enquanto o decoder usa essas representações para gerar a saída. Para tradução automática, isso é natural: encoder lê o inglês, decoder escreve o francês.
Só que dois caminhos divergiram logo depois. O BERT (Google, 2018) ficou só com o encoder, lendo o texto nos dois sentidos simultaneamente. Bom para classificação e compreensão de texto, ruim para geração. O GPT (OpenAI, 2018) ficou só com o decoder, gerando texto da esquerda para a direita, um token de cada vez. É essa variante “decoder-only” que todos os LLMs de geração usam hoje, incluindo o Claude, o Llama e o Gemini.
O Transformer substituiu a recorrência por atenção paralela sobre todos os tokens simultaneamente, eliminando o vanishing gradient estrutural e tornando o treinamento ordens de magnitude mais rápido. Claude, GPT, Gemini e Llama são todos Transformers.
O que existe hoje e que domina o mercado de IA generativa são os Modelos de Linguagem de Grande Escala (LLMs, de Large Language Models). Não são sistemas com consciência, nem “inteligência” no sentido filosófico do termo. São redes neurais artificiais treinadas sobre volumes absurdos de texto (livros, código-fonte, artigos científicos, páginas da web, fóruns, documentação técnica) para prever, com alta probabilidade, qual token vem depois de uma sequência de tokens.
O segundo ingrediente fundamental é o RLHF (Reinforcement Learning from Human Feedback), já explicado mais acima. É essa fase que transforma um “cuspidor de letras” em algo que parece, de fato, um assistente.
Como um Modelo de Linguagem Funciona Por Dentro?
Como já falamos antes, a arquitetura que domina o campo desde 2017 é o Transformer. O mecanismo central é a atenção multi-cabeça (multi-head attention).
Simplificando: para cada token na sequência de entrada, o modelo calcula quanto “atenção” deve prestar a cada outro token na sequência. Se você escreve “O banco estava quebrado porque estava cheio d’água”, o modelo precisa entender que “estava” no final da frase se refere ao banco (o objeto físico), não à instituição financeira. O mecanismo de atenção resolve essa ambiguidade analisando as relações entre todos os tokens simultaneamente. O ‘multi‘ em multi-head significa que esse cálculo de atenção roda em paralelo várias vezes, cada ‘cabeça‘ aprendendo a prestar atenção em aspectos diferentes da relação entre tokens: uma cabeça pode capturar relações sintáticas, outra semânticas, outra de correferência. Os resultados são concatenados e projetados numa representação unificada.
Esse processamento acontece em múltiplas camadas. Cada camada aplica atenção e transforma as representações. Modelos maiores têm mais camadas, mais cabeças de atenção e vetores de maior dimensão. O resultado é uma representação cada vez mais abstrata e contextualizada do texto.
Na prática, quando você submete uma pergunta ao Claude, o seguinte acontece:
- Seu texto é tokenizado (dividido em tokens numéricos via um vocabulário específico do modelo)
- Os tokens passam por camadas de embedding (cada token vira um vetor denso)
- Essas representações percorrem as camadas de atenção do Transformer
- A camada final projeta a representação no vocabulário e calcula probabilidades para o próximo token
- O modelo seleciona um token, adiciona ao contexto e o processo se repete
Esse loop de geração token a token é chamado de inferência. É computacionalmente intenso, especialmente para modelos grandes. Um modelo de 70 bilhões de parâmetros como o Llama 3.1 70B requer dezenas de gigabytes de VRAM só para carregar os pesos em memória, sem contar o overhead de inferência. É por isso que GPUs dominam esse mercado e frameworks como o TensorRT-LLM da NVIDIA existem: otimizar cada etapa desse loop para extrair o máximo do hardware disponível.
Os Dois Modos de Usar IA Hoje: Chat e API
Se você está lendo este blog, provavelmente já usa IA de, pelo menos, um jeito: pela interface web. Você abre o Claude, o ChatGPT ou o Gemini no navegador, digita sua pergunta e recebe a resposta na tela. É a interface de chat. Simples, acessível, zero configuração.
Só que esse modelo de uso tem limites óbvios. Você não consegue automatizar nada. Não consegue integrar a resposta num script Python. Não consegue fazer o modelo editar um arquivo no seu projeto sem copiar e colar manualmente. A interface web é ótima para exploração e consultas avulsas, mas péssima para qualquer coisa que exija integração com o seu fluxo de trabalho.
É aqui que o segundo modo de usar uma IA: pela API. É ela que separa quem usa IA de quem integra IA.
O Que é uma API e Como Ela Funciona
API (Application Programming Interface) é um conjunto de regras e especificações que define como dois sistemas de software se comunicam entre si. Não é um conceito exclusivo de IA, já que toda a internet moderna funciona sobre APIs.
Quando o aplicativo do seu banco consulta seu saldo, ele faz uma chamada à API do banco. Quando o Airbnb exibe um mapa do Google, está consumindo a API do Google Maps. Quando você usa “Entrar com Google” num site qualquer, está usando a API de autenticação OAuth do Google.
No contexto de LLMs, a API funciona assim: você envia uma requisição HTTP POST para um endpoint específico (um endereço URL de uma rota do servidor que aceita requisições) com um payload JSON no corpo da requisição. Esse JSON descreve sua pergunta, o modelo que quer usar, parâmetros de geração (temperatura, número máximo de tokens, etc) e sua chave de autenticação (o API key).
Um exemplo concreto, usando a API da Anthropic:
curl https://api.anthropic.com/v1/messages \
-H "x-api-key: $ANTHROPIC_API_KEY" \
-H "anthropic-version: 2023-06-01" \
-H "content-type: application/json" \
-d '{
"model": "claude-sonnet-4-20250514",
"max_tokens": 1024,
"messages": [
{"role": "user", "content": "Explique o que é um ponteiro em C."}
]
}'
O servidor processa a requisição, executa a inferência no modelo e devolve uma resposta JSON com o texto gerado. Esse JSON pode ser parseado por qualquer linguagem de programação e integrado em qualquer sistema.
A chave de API (o $ANTHROPIC_API_KEY no exemplo acima) é um token de autenticação que identifica você como usuário autorizado e permite que o provedor do modelo controle o acesso, aplique rate limits (limites de requisições por unidade de tempo) e cobre pelo uso. Ela funciona como uma senha especializada. Por isso, NUNCA revele API keys em repositórios públicos!
Esse modelo de acesso via API é o que permite que ferramentas como editores de código, agentes de terminal, pipelines de CI/CD e qualquer outro software usem LLMs como “backend de inteligência” sem precisar reinventar o modelo de linguagem do zero.
O Problema das Ferramentas de IA para Desenvolvedores
Quem usa IA para programar já passou por alguma versão desse ciclo: testa uma ferramenta, gosta, aí vê a fatura e deixa de gostar!!
O Cursor foi a primeira que eu experimentei com seriedade. A proposta é boa: um editor completo com IA integrada, que entende o contexto do projeto e sugere código de forma mais inteligente que um simples autocomplete. Só que o aprendizado não é trivial (é um editor novo, com lógica própria, que você precisa aprender do zero) e o preço do Cursor Pro, US$ 20/mês, ainda cobra por uso extra quando você passa do limite (cursor.com/pricing). O GitHub Copilot Enterprise chega a US$ 39/usuário/mês (github.com/features/copilot). Para quem usa pesado, o custo de tokens nas APIs da Anthropic e OpenAI pode ultrapassar isso facilmente.
Existe o caminho oposto: ferramentas de linha de comando que funcionam no modelo BYOK (Bring Your Own Key), onde você traz a própria API key e paga diretamente pelo que usa, sem markup de intermediário. Historicamente, essas ferramentas eram “brutas”: sem suporte a múltiplos provedores, sem gerenciamento de sessão, sem integração real com o contexto do projeto. Funcionavam como um chat no terminal, nada mais.
O Claude Code, da Anthropic, avançou bastante nisso. Roda no terminal, entende o projeto, age de forma autônoma. Só que é amarrado ao ecossistema da Anthropic. Quer usar Gemini? Groq? Um modelo local via Ollama? Fora.
O OpenCode entra exatamente nessa lacuna!
OpenCode: O Agente que Vive no Terminal
O OpenCode é um agente de IA open source desenvolvido pela equipe da SST (Anomaly), os mesmos criadores do framework SST para infraestrutura serverless. Ele roda no terminal, via TUI (Terminal User Interface), com uma interface interativa construída em Go usando a biblioteca Bubble Tea.
A filosofia de design é que o terminal já é o ambiente natural do desenvolvedor e não faria sentido sair dele para consultar IA, copiar código, colar no editor, ajustar manualmente e repetir. O OpenCode elimina esse ciclo ineficiente.
A instalação é um único comando:
curl -fsSL https://opencode.ai/install | bash
No macOS e Linux via Homebrew:
brew install anomalyco/tap/opencode
No Windows, a recomendação oficial é usar WSL (Windows Subsystem for Linux). Existem alternativas via Chocolatey (choco install opencode), Scoop (scoop install opencode) e npm, mas a experiência no WSL é significativamente melhor.
Uma vez instalado, você navega até o diretório do projeto e executa:
cd /caminho/do/seu/projeto
opencode
O TUI abre imediatamente. Execute /init e o agente analisa a estrutura do projeto, reconhece padrões de código e gera um arquivo AGENTS.md na raiz. Esse arquivo é o “briefing” do agente: ele define o contexto do projeto, as convenções usadas, dependências relevantes e qualquer instrução específica que você queira que o agente siga (já falamos dele lá em cima, lembram?). Se você usa o GitHub, pode dar Commite nesse arquivo junto com o restante do projeto.
Por Que o OpenCode é Diferente
Suporte a mais de 75 provedores de modelos. Claude, GPT, Gemini, Grok, AWS Bedrock, Azure OpenAI, Together AI, Fireworks AI, OpenRouter e modelos locais via Ollama. Você conecta qualquer provedor usando o comando /connectdentro do TUI. O agente trata todos como intercambiáveis: você pode estar no meio de uma sessão usando Claude Sonnet e mudar para um modelo Qwen local sem perder o contexto.
O modelo BYOK. Você paga diretamente pelo que usa, sem markup de intermediário. Para projetos que usam muito o agente, isso pode representar uma economia considerável em relação a assinaturas fixas.
Ferramentas nativas integradas ao agente. O OpenCode não é só um chat que você usa para gerar código e copiar manualmente. O agente tem acesso direto a um conjunto de ferramentas que opera autonomamente:
- Leitura, escrita e edição de arquivos (
read,write,edit,patch) - Execução de comandos shell (
bash,sh) - Busca por conteúdo em arquivos (
grep,glob) - Navegação por definições, referências e símbolos via LSP (Language Server Protocol)
Isso significa que você pode pedir “adicione autenticação JWT nessa rota” e o agente vai ler os arquivos relevantes, escrever as mudanças, rodar os testes e reportar o resultado. Sem copiar e colar.
Plan Mode e Build Mode. Antes de tocar em qualquer arquivo, você pode colocar o agente em Plan Mode (tecla Tab). Ele descreve o que pretende fazer, arquivo por arquivo, mudança por mudança. Você revisa, dá feedback, pede ajustes. Quando estiver satisfeito, alterna para Build Mode e o agente executa. Para mudanças que envolvem muitos arquivos ou lógica complexa, esse ciclo de revisão é valioso.
Sessões múltiplas e persistentes. Diferente de um chat web que você fecha e perde o contexto, o OpenCode armazena as sessões localmente. Você pode ter uma sessão para refatoração, outra para debug, outra para escrever testes, e alternar entre elas sem perder histórico. /share gera um link para compartilhar uma sessão com o time (opt-in, nada é compartilhado por padrão).
Arquitetura cliente/servidor. O OpenCode pode rodar em modo servidor, expondo uma API local. Isso permite que o TUI seja apenas um dos clientes: extensões de IDE, aplicações desktop e até clientes mobile podem se conectar ao mesmo processo rodando na máquina. A extensão para VS Code já está disponível no marketplace.
LSP integration. O agente conecta ao Language Server do seu projeto. Isso não é trivial: significa que o OpenCode tem acesso a informações de tipo, assinaturas de funções, caminhos de importação e diagnósticos de erro, não apenas ao texto cru dos arquivos. A diferença de qualidade nas sugestões é perceptível, especialmente em TypeScript e Go.
MCP (Model Context Protocol). Protocolo aberto para conectar agentes a ferramentas e serviços externos. Você configura servidores MCP no arquivo de configuração do OpenCode e as ferramentas ficam disponíveis automaticamente para o agente. Bancos de dados, APIs externas, gerenciadores de tarefas, serviços de busca: qualquer coisa que exponha um servidor MCP pode ser usada pelo agente como ferramenta nativa.
Detalhe: este NÃO é um post patrocinado, ok? Estou colocando aqui porque achei realmente fantástico!
Três Formas de Usar Modelos Abertos com o OpenCode
Antes de entrar na configuração, vale entender o que está disponível, porque as opções têm perfis de uso completamente diferentes. São três caminhos: NIM remoto, NIM local e Ollama. Cada um serve um cenário específico.
NIM Remoto: O Caminho Mais Simples (e Gratuito)
O build.nvidia.com é o catálogo oficial de APIs da NVIDIA, onde cada modelo roda dentro de um container otimizado com TensorRT-LLM na infraestrutura DGX Cloud. Você não instala nada, não precisa de GPU, não configura Docker. Cadastra uma conta no NVIDIA Developer Program (gratuito, basta um e-mail), gera uma API key com prefixo e começa a usar.
A tier gratuita opera com rate limits de 40 requisições por minuto para a maioria dos modelos. Parece pouco, mas na prática não é. Cada requisição corresponde a uma mensagem enviada ao modelo: você digita, o agente processa, você lê a resposta, analisa o código, decide o próximo passo e só então manda a próxima mensagem. O ritmo humano de trabalho raramente passa de 10 a 15 requisições por minuto numa sessão normal. O limite de 40 só vira problema em dois cenários: scripts automatizados que chamam a API em loop sem pausa ou uso simultâneo da mesma API key em múltiplos terminais ao mesmo tempo. Para o fluxo de trabalho que estamos descrevendo aqui, você não vai sentir.
O catálogo é extenso (147 modelos na data de publicação deste post!), incluindo a família completa Llama 3.1 (8B, 70B, 405B), Qwen 2.5 Coder 32B, Nemotron, Gemma 4, DeepSeek V4, modelos de visão como LLaVA, modelos de embedding (NV-EmbedQA), modelos de reranking, modelos especializados em biologia (ESMFold) e física. Para desenvolvimento de software, os mais relevantes são o DeepSeek V4, Llama 3.1 70B, o Qwen 2.5 Coder 32B e o Nemotron.
A API do NIM é compatível com o padrão OpenAI. O endpoint base é e as chamadas seguem exatamente o mesmo formato da API da OpenAI. Qualquer ferramenta que aceite “OpenAI custom endpoint” conecta no NIM sem modificação e o OpenCode é uma delas.
Para configurar no OpenCode, edite ~/.config/opencode/opencode.json :
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"nvidia": {
"name": "NVIDIA NIM",
"apiKey": "nvapi-SEU_KEY_AQUI",
"models": {
"llama-3.1-70b": {
"name": "Llama 3.1 70B",
"api": "https://integrate.api.nvidia.com/v1",
"id": "meta/llama-3.1-70b-instruct"
},
"qwen-coder": {
"name": "Qwen 2.5 Coder 32B",
"api": "https://integrate.api.nvidia.com/v1",
"id": "qwen/qwen2.5-coder-32b-instruct"
}
}
}
}
}
Pronto. O modelo roda nos servidores da NVIDIA, você não gasta nada e o OpenCode interage com ele exatamente como interagiria com o Claude ou o GPT.
O que a NVIDIA e o desenvolvedores de modelos ganham com isso? Vale a pena destrinchar o papel de cada um nessa engrenagem:
1. A Validação de Infraestrutura e Domínio de Mercado pela NVIDIA
A NVIDIA não está prestando caridade; ela está usando esse volume gigantesco de acessos do uso gratuito para estressar a própria infraestrutura.
-
O laboratório do TensorRT-LLM: O TensorRT-LLM é a menina dos olhos da NVIDIA para otimização de inferência. Ao abrir o NIM remotamente, eles testam em tempo real como o software lida com o gerenciamento de memória (KV Cache), quantização, concorrência de requisições e paralelismo de modelos em clusters de GPUs H100/A100 (na DGX Cloud).
-
Telemetria de Hardware: Eles coletam dados massivos sobre o comportamento das placas sob cargas de trabalho imprevisíveis (erros de driver, picos de temperatura, latência sob gargalo).
2. A Vitrine dos Desenvolvedores de Modelos
Para criadores de modelos abertos (como a Meta com o Llama 3.3, Google com o Gemma, DeepSeek, etc.), ter seus modelos hospedados no catálogo da NVIDIA é marketing puro e validação técnica.
-
Eles conseguem provar que seus modelos rodam com performance extrema quando otimizados nativamente pela stack da NVIDIA.
-
É um incentivo para que empresas olhem para esses modelos abertos e pensem: “Ok, isso roda muito rápido. Vale a pena eu trazer para dentro de casa comprando hardware da NVIDIA”.
3. O “Beta Tester” (e aisca de conversão)
Ao usar aplicativos conectados a essas APIs remotas (como o OpenCode usando chaves de teste da NVIDIA), você se encaixa perfeitamente em duas funções:
-
Massa de Teste (Telemetry & Edge Cases): Usuários reais fazem perguntas bizarras, geram prompts gigantescos, quebram o contexto do modelo e enviam requisições simultâneas que nenhum script de simulação automatizado conseguiria replicar com perfeição. Você ajuda a mapear os limites do sistema gratuitamente.
-
O Funil de Vendas Corporativo: A NVIDIA agora oferece chaves de API gratuitas baseadas em rate limits. Para o desenvolvedor individual ou para validar uma Prova de Conceito (POC), isso é ótimo porque permite testes contínuos sem custos ou risco de zerar o saldo de créditos. Mas a pegadinha comercial continua a mesma: esses endpoints públicos e gratuitos são estritamente para experimentação e não possuem garantia de uptime ou SLAs para produção. Se a sua aplicação crescer e você precisar de estabilidade, alta disponibilidade e conformidade jurídica, o funil vai empurrar o usuário para o próximo passo: assinar o NVIDIA AI Enterprise para rodar os contêineres NIM na sua própria infraestrutura ou contratar instâncias dedicadas em nuvens parceiras.
No final, é uma relação ganha-ganha e todo mundo fica feliz: a NVIDIA testa o TensorRL-LLM e as placas, os desenvolvedores de modelos testam modelos e o usuário tem tudo isso de graça para ser o beta tester deles!
NIM Local: Performance Máxima, Complexidade Maior
O NIM local é para quem tem hardware NVIDIA dedicado e quer extrair o máximo dele. A diferença em relação ao Ollama e outras soluções locais é operacional: os containers NIM são pré-otimizados para arquiteturas específicas de GPU NVIDIA, entregando throughput próximo ao pico sem configuração manual de engines de inferência. Os benchmarks da NVIDIA mostram um Llama 3.1 8B servido via NIM num H100 SXM chegando a aproximadamente 1.201 tokens/s.
O deployment local requer GPU NVIDIA (H100, H200, B200 ou RTX para modelos menores), Docker instalado e uma NGC API key. A licença gratuita do Developer Program permite self-hosting em até 16 GPUs para pesquisa e desenvolvimento. Uso em produção requer licença NVIDIA AI Enterprise, com trial gratuito de 90 dias disponível.
Os containers estão disponíveis no NGC (NVIDIA GPU Cloud). Para rodar o Llama 3.1 8B localmente:
export NGC_API_KEY=<sua_api_key>
docker run --gpus all \
-e NGC_API_KEY=$NGC_API_KEY \
-p 8000:8000 \
nvcr.io/nim/meta/llama-3.1-8b-instruct:1.13.1
O servidor sobe e expõe uma API OpenAI-compatível na porta 8000. No OpenCode, o endpoint local entra como provider customizado, com qualquer string no campo de API key (o servidor local não valida autenticação por padrão). O código escrito durante a fase de prototipagem com a API remota gratuita funciona sem modificação quando você migra para NIM local, porque a interface é idêntica. Só troca o endpoint.
O NIM local faz sentido em três cenários: você tem GPU NVIDIA potente e quer latência mínima, trabalha em ambiente com restrições de privacidade onde dados não podem sair da máquina ou precisa de throughput maior que o rate limit gratuito permite.
Ollama: O Caminho Mais Simples para Rodar Localmente
O Ollama foi lançado em 2023 e se tornou o padrão de fato para rodar LLMs localmente, com suporte a modelos como Llama, Gemma, Mistral, Qwen e DeepSeek. A proposta é facilidade máxima: instala, baixa o modelo, usa. Sem Docker, sem NGC, sem configuração de container.
Instalação em um comando:
# macOS e Linux
curl -fsSL https://ollama.com/install.sh | sh
# macOS via Homebrew
brew install ollama
# Windows: instalador disponível em ollama.com/download
Baixar e rodar um modelo:
<span class="token token"># Qwen 2.5 Coder 7B</span>
ollama run qwen2.5-coder:7b
<span class="token token"># Llama 3.1 8B</span>
ollama run llama3.1:8bO Ollama inicia um servidor local na porta 11434 e expõe uma API OpenAI-compatível em http://localhost:11434/v1. Para conectar no OpenCode:
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"ollama": {
"npm": "@ai-sdk/openai-compatible",
"options": {
"baseURL": "http://localhost:11434/v1"
},
"models": {
"qwen2.5-coder:7b": {
"name": "Qwen 2.5 Coder 7B"
}
}
}
}
}
Um detalhe importante: o Ollama tem dois endpoints, o nativo (/api) e o OpenAI-compatível (/v1). O OpenCode usa obrigatoriamente o (/v1), não o nativo.
O Ollama define um contexto padrão de 4K tokens, pequeno demais para uso com agente de código. Para tarefas sem agentes de código, o recomendado é pelo menos 16K:
ollama run qwen2.5-coder:7b
/set parameter num_ctx <span class="token token">16384</span>
/save qwen2.5-coder:7b-16k
/byeOllama vs NIM local: qual a diferença?
Ambos rodam modelos localmente, mas com abordagens distintas. O Ollama usa o llama.cpp por baixo, com modelos no formato GGUF e quantização. Funciona em CPU se não tiver GPU, roda em Mac com Apple Silicon via Metal, é simples de instalar e gerenciar. O NIM local roda containers Docker com TensorRT-LLM compilado especificamente para a arquitetura da sua GPU NVIDIA, entregando throughput significativamente maior na mesma GPU, mas exigindo mais setup, mais espaço em disco e hardware NVIDIA obrigatoriamente.
Resumindo: O que usar?
Para uso pessoal e desenvolvimento casual: Ollama. Para quem tem uma RTX dedicada e quer extrair performance máxima: NIM local. Para quem não tem GPU ou quer começar sem instalar nada: NIM remoto.
| NIM Remoto | NIM Local | Ollama | |
|---|---|---|---|
| GPU necessária | Não | Sim (NVIDIA) | Não (mas recomendada) |
| Custo | Gratuito (rate limit) | Gratuito (dev) | Gratuito |
| Setup | 5 minutos | Complexo | 5 minutos |
| Dados saem da máquina | Sim | Não | Não |
| Performance | Alta (DGX Cloud) | Máxima (local) | Boa (llama.cpp) |
| Endpoint OpenCode | integrate.api.nvidia.com/v1 |
localhost:8000/v1 |
localhost:11434/v1 |
Como Conectar o OpenCode ao NVIDIA NIM
O OpenCode tem suporte nativo ao padrão de “custom provider” OpenAI-compatível, que é exatamente o formato que o NIM usa.
Passo 1: Gerar a API Key no build.nvidia.com
Acesse build.nvidia.com, faça login com sua conta NVIDIA Developer (ou crie uma, é gratuito), e gere uma API key em build.nvidia.com/settings/api-keys. A chave começa com nvapi-.
Passo 2: Configurar o provider no OpenCode
O arquivo de configuração do OpenCode fica em ~/.config/opencode/config.json. Adicione o provider do NIM:
{
"providers": {
"nvidia": {
"name": "NVIDIA NIM",
"apiKey": "nvapi-SEU_API_KEY_AQUI",
"models": {
"llama-3.1-70b": {
"name": "Llama 3.1 70B",
"api": "https://integrate.api.nvidia.com/v1",
"id": "meta/llama-3.1-70b-instruct"
},
"qwen-2.5-coder": {
"name": "Qwen 2.5 Coder 32B",
"api": "https://integrate.api.nvidia.com/v1",
"id": "qwen/qwen2.5-coder-32b-instruct"
}
}
}
}
}
Outro modo é de dentro do TUI do OpenCode, onde você usa o comando /connect e seleciona “Custom OpenAI-compatible provider”, preenchendo o endpoint base e a API key interativamente.
Passo 3: Verificar a conexão
Abra um projeto e rode opencode. No TUI, o seletor de modelos (normalmente acessível via Ctrl+M ou pelo menu) vai listar os modelos do NIM que você configurou. Selecione um e faça uma pergunta de teste.
Configuração para NIM local (container Docker)
Se você está rodando o container NIM localmente, o endpoint é diferente:
{
"providers": {
"nim-local": {
"name": "NIM Local",
"apiKey": "qualquer-string-aqui",
"models": {
"llama-local": {
"name": "Llama 3.1 8B Local",
"api": "http://localhost:8000/v1",
"id": "meta/llama-3.1-8b-instruct"
}
}
}
}
}
Para o container local, o API key pode ser qualquer string (o servidor local não valida autenticação por padrão), mas o campo precisa existir para o OpenCode não rejeitar a configuração.
O Fluxo de Trabalho na Prática
Eis um exemplo concreto de como a combinação OpenCode + NIM transforma um fluxo de desenvolvimento.
Você está trabalhando num projeto Go e precisa adicionar validação de input a um handler HTTP. Abre o terminal no diretório do projeto, executa opencode, e o TUI inicia com o Llama 3.1 70B via NIM selecionado.
Primeiro, coloca o agente em Plan Mode (Tab) e descreve o que quer:
Preciso adicionar validação de input no handler POST /users em @internal/handlers/users.go.
Os campos obrigatórios são: name (string, min 2 chars), email (email válido),
role (enum: admin, editor, viewer). Retorne 422 com os erros detalhados se a validação falhar.
O agente lê o arquivo internal/handlers/users.go via LSP, consulta a estrutura do projeto, identifica as dependências de validação já usadas (se existirem) e apresenta o plano: quais structs vai criar, quais funções vai modificar, onde vai adicionar os testes unitários.
Você revisa, pede um ajuste (“use a biblioteca go-playground/validator que já está no go.mod”), e alterna para Build Mode. O agente executa as mudanças, roda go test ./... via ferramenta bash e reporta o resultado. Se os testes passarem, você tem um diff limpo para revisar antes de commitar. Se falharem, o agente analisa o erro e propõe a correção.
Esse é o fluxo que a combinação OpenCode + qualquer LLM decente torna possível hoje. A diferença de usar o NIM é que você não está pagando US$ 20/mês de assinatura nem gastando tokens do Claude para tarefas onde o Llama 3.1 70B (gratuito no NIM) entrega 90% da qualidade.
O comando /undo desfaz qualquer mudança feita pelo agente, arquivo a arquivo, e o /redo as reaplicam. Para projetos sem Git configurado, esse sistema de undo é especialmente útil.
Quando Usar o Quê
A combinação OpenCode + NIM não substitui tudo e não seria honesto fingir que substitui.
Para tarefas que exigem raciocínio longo, contexto extenso, análise de arquitetura complexa ou criação de sistemas do zero, os modelos frontier (Claude Sonnet/Opus, GPT-4o, Gemini 2.5 Pro) ainda entregam resultados significativamente melhores que o Llama 3.1 70B. Para esse tipo de tarefa, faz sentido usar o OpenCode com o provedor Claude ou OpenAI via BYOK.
O NIM gratuito brilha em tarefas mais delimitadas: completar uma função específica, escrever testes unitários para código existente, fazer refatoração localizada, explicar um trecho de código, gerar boilerplate code. São as tarefas que representam a maioria do volume diário de um desenvolvedor, mas não o pico de complexidade.
A arquitetura multi-provider do OpenCode é justamente o que torna esse balanceamento natural: você configura ambos os providers, seleciona o modelo conforme a complexidade da tarefa e paga (ou não paga) de acordo com o que cada tarefa realmente exige.
Para desenvolvimento offline ou em ambientes com restrições de privacidade, os containers NIM locais são a opção correta. Um RTX 4090 (24GB VRAM) roda o Llama 3.1 8B com conforto e consegue rodar o 70B com quantização Q4 em velocidade utilizável. Uma RTX 3090 ou 4080 opera o 8B sem dificuldade. Para o 70B em FP16 completo, você precisa de pelo menos 80GB de VRAM, o que significa dois A100 ou H100, já fora do alcance do hardware de consumidor.
A barreira de entrada para usar LLMs de qualidade no fluxo de desenvolvimento nunca foi tão baixa: Terminal + API key gratuita + agente open source. Não precisa de assinatura, não precisa de VPN para datacenter corporativo, não precisa de aprovação do departamento de TI. Você instala, configura em cinco minutos e começa a trabalhar.
Quer fazer um app simples para celular? Quer fazer aquele programinha para uma função simples que você nunca encontrou a solução exata? Quer fazer um pequeno programa em uma linguagem que você não domina completamente? Aqui está a solução!
Por hoje é isso, pessoal!